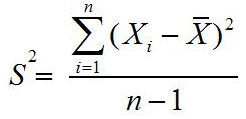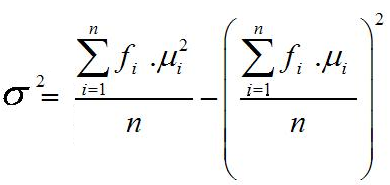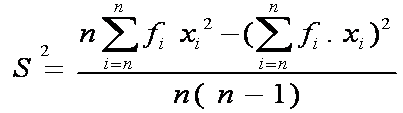TUGAS BAB V. MOMENT, KEMIRINGAN DAN KURTOSIS
BAB V. MOMENT, KEMIRINGAN DAN KURTOSIS
Skewness
and Kurtosis
Rata-rata dan ukuran penyebaran dapat menggambarkan distribusi data
tetapi tidak cukup untuk menggambarkan sifat distribusi. Untuk dapat
menggambarkan karakteristik dari suatu distribusi data, kita menggunakan
konsep-konsep lain yang dikenal sebagai kemiringan (skewness) dan
keruncingan (kurtosis).
Skewness
Kemiringan (skewness) berarti ketidaksimetrisan. Sebuah distribusi
dikatakan simetris apabila nilai-nilainya tersebar merata disekitar
nilai rata-ratanya.
Sebagai contoh, distribusi data berikut simetris terhadap nilai rata-ratanya, 3.
x 1 2 3 4 5
frek f) 5 9 12 9 5
Pada contoh gambar berikut, distribusi data tidak simetris.
Gambar
pertama miring (menjulur) ke arah kiri dan gambar ke-2 miring ke arah
kanan.
Pada distribusi data yang simetris, mean, median dan modus bernilai
sama.
Beberapa langkah-langkah perhitungan digunakan untuk menyatakan arah dan
tingkat kemiringan dari sebaran data. Langkah-langkah tersebut
diperkenalkan oleh Pearson.
Koefisien kemiringan(Coefficient of Skewness):
Interpretasi: Untuk distribusi data yang simetris, Sk = 0. Apabila
distribusi data menjulur ke kiri (negatively skewed), Sk bernilai
negatif, dan apabila menjulur ke kanan (positively skewed), SK bernilai
positif. Kisaran untuk SK antara -3 dan 3.
Ukuran kemiringan yang lain adalah koefisien β1 (baca 'beta-satu'):
dimana:
Interpretasi:
Distribusi dikatakan simetris apabila nilai b1 = 0. Skewness positif
atau negatif tergantung pada nilai b1 apakah bernilai positif atau
negatif.
Ukuran Skewness yang sering digunakan:
Skewness Populasi:
Skewness Sampel:
Source: D. N. Joanes and C. A. Gill. "Comparing Measures of Sample
Skewness and Kurtosis". The Statistician 47(1):183–189.
atau formula berikut (MS Excel):
s = standar deviasi
NB: kedua formula di atas menghasilkan nilai skewness yang sama
Interpretasi:
Distribusi dikatakan simetris apabila nilai g1 = 0. Skewness positif
atau negatif tergantung pada nilai g1 apakah bernilai positif atau
negatif.
Menurut Bulmer, M. G., Principles of Statistics (Dover, 1979):
• highly skewed: jika skewness kurang dari −1 atau lebih dari +1
• moderately skewed: jika skewness antara −1 dan −½ atau antara +½ dan +1.
•
approximately symmetric: jika skewness is berada di antara −½ dan +½.
Kurtosis
Kurtosis merupakan ukuran untuk mengukur keruncingan distribusi data.
Distribusi pada gambar di atas semuanya simetris terhadap nilai
rata-ratanya. Namun bentuk ketiganya tidak sama. Kurva berwarna biru
dikenal sebagai mesokurtik (kurva normal), kurva berwarna merah dikenal
sebagai leptokurtik (kurva runcing) dan kurva berwarna hijau dikenal
sebagai platikurtik (kurva datar).
Kurtosis dihitung dengan menggunakan koefisien Pearson, β2 (baca 'beta -
dua').
dimana:
Ukuran Kurtosis yang sering digunakan:
Kurtosis Populasi:
Kurtosis:
Excess Kurtosis:
Kurtosis Sampel:
atau formula berikut (MS Excel):
s = standar deviasi
NB: Excel menggunakan nilai Excess Kurtosis. Hasil perhitungan dari
kedua formula di atas, menghasilkan nilai yang sama
Interpretasi:
Distribusi dikatakan:
• Mesokurtik (Normal) jika b2 = 3
• Leptokurtik jika b2 > 3
•
platikurtik jika b2 < 3
Analisis Korelasi Product Moment dalam Statistika
Analisis korelasi merupakan salah satu teknik statistik yang digunakan
untuk menganalisis hubungan antara dua variabel atau lebih yang bersifat
kuantitatif. Salah satu dari analisis korelasi tersebut adalah analisis
korelasi product moment (Pearson). Variabel yang digunakan disini
terbagi dua yaitu variabel bebas (x) dengan variabel terikat (y), dengan
ketentuan data memiliki syarat-syarat tertentu.
Korelasi Pearson Product Moment (r) dapat diformulasikan sbb:
dengan ketentuan −1 ≤ r ≤ r . Dan interpretasi koefisien korelasi nilai r
ini dapat dirangkum dalam tabel berikut:
Langkah-langkah yang diperlukan untuk uji korelasi Pearson Product
Moment adalah sebagai berikut :
1. Rumuskan hipotesis Ha dan Ho dalam bentuk kalimat.
2. Rumuskan hipotesis Ha dan Ho dalam bentuk statistik.
3. Buat tabel pembantu.
4. Tentukan r
5. Tentukan nilai KP
6. Lakukan uji signifikansi.
7. Tentukan α , dengan derajat bebas db = n − 2 .
8. Tentukan konklusi